有关timm库的笔记

1 什么是 timm 库?
PyTorchImageModels,简称 timm,是一个巨大的 PyTorch 代码集合,包括了一系列:
image models
layers
utilities
optimizers
schedulers
data-loaders / augmentations
training / validation scripts
旨在将各种 SOTA 模型整合在一起,并具有复现 ImageNet 训练结果的能力。
作者github链接:https://github.com/rwightman
timm库链接:https://github.com/rwightman/pytorch-image-models
所有的PyTorch模型及其对应arxiv链接如下:
- Big Transfer ResNetV2 (BiT) - https://arxiv.org/abs/1912.11370
- CspNet (Cross-Stage Partial Networks) - https://arxiv.org/abs/1911.11929
- DeiT (Vision Transformer) - https://arxiv.org/abs/2012.12877
- DenseNet - https://arxiv.org/abs/1608.06993
- DLA - https://arxiv.org/abs/1707.06484
- DPN (Dual-Path Network) - https://arxiv.org/abs/1707.01629
- EfficientNet (MBConvNet Family)
- EfficientNet NoisyStudent (B0-B7, L2) - https://arxiv.org/abs/1911.04252
- EfficientNet AdvProp (B0-B8) - https://arxiv.org/abs/1911.09665
- EfficientNet (B0-B7) - https://arxiv.org/abs/1905.11946
- EfficientNet-EdgeTPU (S, M, L) - https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html
- FBNet-C - https://arxiv.org/abs/1812.03443
- MixNet - https://arxiv.org/abs/1907.09595
- MNASNet B1, A1 (Squeeze-Excite), and Small - https://arxiv.org/abs/1807.11626
- MobileNet-V2 - https://arxiv.org/abs/1801.04381
- Single-Path NAS - https://arxiv.org/abs/1904.02877
- GPU-Efficient Networks - https://arxiv.org/abs/2006.14090
- HRNet - https://arxiv.org/abs/1908.07919
- Inception-V3 - https://arxiv.org/abs/1512.00567
- Inception-ResNet-V2 and Inception-V4 - https://arxiv.org/abs/1602.07261
- MobileNet-V3 (MBConvNet w/ Efficient Head) - https://arxiv.org/abs/1905.02244
- NASNet-A - https://arxiv.org/abs/1707.07012
- NFNet-F - https://arxiv.org/abs/2102.06171
- NF-RegNet / NF-ResNet - https://arxiv.org/abs/2101.08692
- PNasNet - https://arxiv.org/abs/1712.00559
- RegNet - https://arxiv.org/abs/2003.13678
- RepVGG - https://arxiv.org/abs/2101.03697
- ResNet/ResNeXt
- ResNet (v1b/v1.5) - https://arxiv.org/abs/1512.03385
- ResNeXt - https://arxiv.org/abs/1611.05431
- 'Bag of Tricks' / Gluon C, D, E, S variations - https://arxiv.org/abs/1812.01187
- Weakly-supervised (WSL) Instagram pretrained / ImageNet tuned ResNeXt101 - https://arxiv.org/abs/1805.00932
- Semi-supervised (SSL) / Semi-weakly Supervised (SWSL) ResNet/ResNeXts - https://arxiv.org/abs/1905.00546
- ECA-Net (ECAResNet) - https://arxiv.org/abs/1910.03151v4
- Squeeze-and-Excitation Networks (SEResNet) - https://arxiv.org/abs/1709.01507
- Res2Net - https://arxiv.org/abs/1904.01169
- ResNeSt - https://arxiv.org/abs/2004.08955
- ReXNet - https://arxiv.org/abs/2007.00992
- SelecSLS - https://arxiv.org/abs/1907.00837
- Selective Kernel Networks - https://arxiv.org/abs/1903.06586
- TResNet - https://arxiv.org/abs/2003.13630
- Vision Transformer - https://arxiv.org/abs/2010.11929
- VovNet V2 and V1 - https://arxiv.org/abs/1911.06667
- Xception - https://arxiv.org/abs/1610.02357
- Xception (Modified Aligned, Gluon) - https://arxiv.org/abs/1802.02611
- Xception (Modified Aligned, TF) - https://arxiv.org/abs/1802.02611
2 timm库特点:
所有的模型都有默认的API:
- accessing/changing the classifier - get_classifier and reset_classifier
- 只对features做前向传播 - forward_features
所有模型都支持多尺度特征提取 (feature pyramids) (通过create_model函数):
- create_model(name, features_only=True, out_indices=..., output_stride=...)
out_indices 指定返回哪个feature maps to return, 从0开始,out_indices[i]对应着 C(i + 1) feature level。
output_stride 通过dilated convolutions控制网络的output stride。大多数网络默认 stride 32 。
所有的模型都有一致的pretrained weight loader,adapts last linear if necessary。
训练方式支持:
NVIDIA DDP w/ a single GPU per process, multiple processes with APEX present (AMP mixed-precision optional)
PyTorch DistributedDataParallel w/ multi-gpu, single process (AMP disabled as it crashes when enabled)
PyTorch w/ single GPU single process (AMP optional)
动态的全局池化方式可以选择:average pooling, max pooling, average + max, or concat([average, max]),默认是adaptive average。
Schedulers:
Schedulers 包括step,cosinew/ restarts,tanhw/ restarts,plateau 。
Optimizer:
rmsprop_tf adapted from PyTorch RMSProp by myself. Reproduces much improved Tensorflow RMSProp behaviour.
radam by Liyuan Liu (https://arxiv.org/abs/1908.03265)
novograd by Masashi Kimura (https://arxiv.org/abs/1905.11286)
lookahead adapted from impl by Liam (https://arxiv.org/abs/1907.08610)
fused
optimizers by name with NVIDIA Apex installed adamp and sgdp by Naver ClovAI (https://arxiv.org/abs/2006.08217)
adafactor adapted from FAIRSeq impl (https://arxiv.org/abs/1804.04235)
adahessian by David Samuel (https://arxiv.org/abs/2006.00719)
3 timm库 vision_transformer.py代码解读:
代码来自:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
对应的论文是ViT,是除了官方开源的代码之外的又一个优秀的PyTorch implement。
An Image Is Worth 16 x 16 Words: Transformers for Image Recognition at Scale https://arxiv.org/abs/2010.11929
另一篇工作DeiT也大量借鉴了timm库这份代码的实现:
Training data-efficient image transformers & distillation through attention https://arxiv.org/abs/2012.12877
vision_transformer.py:
代码中定义的变量的含义如下:
img_size:tuple类型,里面是int类型,代表输入的图片大小,默认是224。
patch_size:tuple类型,里面是int类型,代表Patch的大小,默认是16。
in_chans:int类型,代表输入图片的channel数,默认是3。
num_classes:int类型classification head的分类数,比如CIFAR100就是100,默认是1000。
embed_dim:int类型Transformer的embedding dimension,默认是768。
depth:int类型,Transformer的Block的数量,默认是12。
num_heads:int类型,attention heads的数量,默认是12。
mlp_ratio:int类型,mlp hidden dim/embedding dim的值,默认是4。
qkv_bias:bool类型,attention模块计算qkv时需要bias吗,默认是True。
qk_scale:一般设置成None就行。
drop_rate:float类型,dropout rate,默认是0。
attn_drop_rate:float类型,attention模块的dropout rate,默认是0。
drop_path_rate:float类型,默认是0。
hybrid_backbone:nn.Module类型,在把图片转换成Patch之前,需要先通过一个Backbone吗?默认是None。
如果是None,就直接把图片转化成Patch。
如果不是None,就先通过这个Backbone,再转化成Patch。
norm_layer:nn.Module类型,归一化层类型,默认是None。
1 导入必要的库和模型:
1 | import math |
2 定义一个字典,代表标准的模型,如果需要更改模型超参数只需要改变_cfg的传入的参数即可。
1 | def _cfg(url='', **kwargs): |
3 default_cfgs代表支持的所有模型,也定义成字典的形式:
vit_small_patch16_224里面的small代表小模型。
ViT的第一步要把图片分成一个个patch,然后把这些patch组合在一起作为对图像的序列化操作,比如一张224 × 224的图片分成大小为16 × 16的patch,那一共可以分成196个。所以这个图片就序列化成了(196, 256)的tensor。所以这里的:
16:就代表patch的大小。
224:就代表输入图片的大小。
按照这个命名方式,支持的模型有:vit_base_patch16_224,vit_base_patch16_384等等。
后面的vit_deit_base_patch16_224等等模型代表DeiT这篇论文的模型。
1 | default_cfgs = { |
4 FFN实现:
1 | class Mlp(nn.Module): |
5 Attention实现:
在python 3.5以后,@是一个操作符,表示矩阵-向量乘法
A@x 就是矩阵-向量乘法A*x: np.dot(A, x)。
1 | class Attention(nn.Module): |
6 包含Attention和Add & Norm的Block实现:
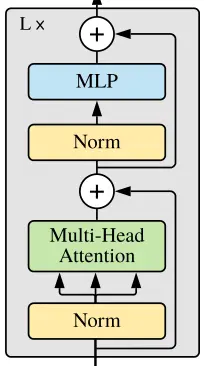
不同之处是: 先进行Norm,再Attention;先进行Norm,再通过FFN (MLP)。
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x7 接下来要把图片转换成Patch,一种做法是直接把Image转化成Patch,另一种做法是把Backbone输出的特征转化成Patch。
7.1直接把Image转化成Patch:
输入的x的维度是:(B, C, H, W) 输出的PatchEmbedding的维度是:(B, 14$\(14, 768),768表示embed_dim,14\)$14表示一共有196个Patches。
1 | class PatchEmbed(nn.Module): |
7.2把Backbone输出的特征转化成Patch:
输入的x的维度是:(B, C, H, W)
得到Backbone输出的维度是:(B, feature_size, feature_size, feature_dim)
输出的PatchEmbedding的维度是:(B, feature_size, feature_size, embed_dim),一共有feature_size * feature_size个Patches。
1 | class HybridEmbed(nn.Module): |
8 以上是ViT所需的所有模块的定义,下面是VisionTransformer 这个类的实现:
8.1 使用这个类时需要传入的变量,其含义已经在本小节一开始介绍。
1 | class VisionTransformer(nn.Module): |
8.2 得到分块后的Patch的数量:
1 | super().__init__() |
8.3 class token:
一开始定义成(1, 1, 768),之后再变成(B, 1, 768)。
1 | self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) |
8.4 定义位置编码:
1 | self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) |
8.5 把12个Block连接起来:
1 | self.pos_drop = nn.Dropout(p=drop_rate) |
8.6 表示层和分类头:
表示层输出维度是representation_size,分类头输出维度是num_classes。
1 | # Representation layer |
8.7 初始化各个模块:
函数trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.)的目的是用截断的正态分布绘制的值填充输入张量,我们只需要输入均值mean,标准差std,下界a,上界b即可。
self.apply(self._init_weights)表示对各个模块的权重进行初始化。apply函数的代码是:
1 | for module in self.children(): |
递归地将fn应用于每个子模块,相当于在递归调用fn,即_init_weights这个函数。
也就是把模型的所有子模块的nn.Linear和nn.LayerNorm层都初始化掉。
1 | trunc_normal_(self.pos_embed, std=.02) |
8.8 最后就是整个ViT模型的forward实现:
1 | def forward_features(self, x): |
9 下面是Training data-efficient image transformers & distillation through attention这篇论文的DeiT这个类的实现:
整体结构与ViT相似,继承了上面的VisionTransformer类。
1 | class DistilledVisionTransformer(VisionTransformer): |
再额外定义以下3个变量:
distillation token:dist_token 新的位置编码:pos_embed 蒸馏分类头:head_dist
1 | self.dist_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim)) |
初始化新定义的变量:
1 | trunc_normal_(self.dist_token, std=.02) |
前向函数:
1 | def forward_features(self, x): |
10 对位置编码进行插值:
posemb代表未插值的位置编码权值,posemb_tok为位置编码的token部分,posemb_grid为位置编码的插值部分。 首先把要插值部分posemb_grid给reshape成(1, gs_old, gs_old, -1)的形式,再插值成(1, gs_new, gs_new, -1)的形式,最后与token部分在第1维度拼接在一起,得到插值后的位置编码posemb。
1 | def resize_pos_embed(posemb, posemb_new): |
11 _create_vision_transformer函数用于创建vision transformer:
checkpoint_filter_fn的作用是加载预训练权重。
1 | def checkpoint_filter_fn(state_dict, model): |
12 定义和注册vision transformer模型:
@ register_model这个函数来自timm库model文件夹下的registry.py文件,它的作用是: @ 指装饰器 @register_model代表注册器,注册这个新定义的模型。 存储到_model_entrypoints这个字典中,比如:
1 | _model_entrypoints[vit_base_patch16_224] = _create_vision_transformer('vit_base_patch16_224', pretrained=pretrained, **model_kwargs) |
然后在factory.py的create_model函数中的下面这几行真正创建模型,你以后想创建的任何模型都会使用create_model这个函数,这里说清楚了为什么要用它:
1 | if is_model(model_name): |
比如刚才在main.py里面用了create_model创建模型,如下面代码所示。而create_model就来自factory.py:
1 | model = create_model( |
一共可以选择的模型包括:
ViT系列: vit_small_patch16_224 vit_base_patch16_224 vit_base_patch32_224 vit_base_patch16_384 vit_base_patch32_384 vit_large_patch16_224 vit_large_patch32_224 vit_large_patch16_384 vit_large_patch32_384 vit_base_patch16_224_in21k vit_base_patch32_224_in21k vit_large_patch16_224_in21k vit_large_patch32_224_in21k vit_huge_patch14_224_in21k vit_base_resnet50_224_in21k vit_base_resnet50_384 vit_small_resnet26d_224 vit_small_resnet50d_s3_224 vit_base_resnet26d_224 vit_base_resnet50d_224
DeiT系列: vit_deit_tiny_patch16_224 vit_deit_small_patch16_224 vit_deit_base_patch16_224 vit_deit_base_patch16_384 vit_deit_tiny_distilled_patch16_224 vit_deit_small_distilled_patch16_224 vit_deit_base_distilled_patch16_224 vit_deit_base_distilled_patch16_384
以上就是对timm库 vision_transformer.py代码的分析。
4 如何使用timm库以及 vision_transformer.py代码搭建自己的模型?
在搭建我们自己的视觉Transformer模型时,我们可以按照下面的步骤操作:首先
继承timm库的VisionTransformer这个类。 添加上自己模型独有的一些变量。 重写forward函数。 通过timm库的注册器注册新模型。
我们以ViT模型的改进版DeiT为例:
首先,DeiT的所有模型列表如下:
1 | __all__ = [ |
导入VisionTransformer这个类,注册器register_model,以及初始化函数trunc_normal_:
1 | from timm.models.vision_transformer import VisionTransformer, _cfg |
DeiT的class名称是DistilledVisionTransformer,它直接继承了VisionTransformer这个类:
1 | class DistilledVisionTransformer(VisionTransformer): |
添加上自己模型独有的一些变量:
1 | def __init__(self, *args, **kwargs): |
重写forward函数:
1 |
|
5 timm库 train.py代码解读:
timm库的训练使用结合apex支持的分布式训练,同步bn,以及混合精度的训练方式,其train.py的写法很具有代表性,值得拿出来讨论。因此这篇文章再多加一段,来专门讨论这个train.py。
结合apex支持的分布式训练,同步bn,以及混合精度的训练方式的详细讲解可以参考下面这篇文章:
https://zhuanlan.zhihu.com/p/353587472
在这篇文章中我们使用8步法结合apex支持的分布式训练,同步bn,以及混合精度:
5.1先罗列自己网络的参数:
1 | def parse(): |
local_rank指定了输出设备,默认为GPU可用列表中的第一个GPU。这里这个是必须加的。原因后面讲
5.2在主函数中开头写:
1 | def main(): |
5.3导入数据接口,这里有一点不一样。需要用一个DistributedSampler:
1 | dataset = DAVIS2017(root, 'training') |
5.4之后定义模型:
1 | net = XXXNet(using_amp=True) |
5.5定义优化器,损失函数,定义优化器一定要在把模型搬运到GPU之后:
1 | opt = Adam([{'params': params_low_lr, 'lr': 4e-5}, |
5.6多GPU设置:
1 | net, opt = amp.initialize(net, opt, opt_level="O1") # 字母小写o,不是零。 |
5.7记得loss要这么用:
1 | opt.zero_grad() |
5.8然后在代码底部加入:
1 | if __name__ == '__main__': |
那么这个train.py大体上依然遵循这8步:
https://github.com/rwightman/pytorch-image-models/blob/master/train.py
总结
本文简要介绍了优秀的PyTorch Image Model 库:timm库以及其中的 vision transformer 代码和训练代码。 Transformer 架构早已在自然语言处理任务中得到广泛应用,但在计算机视觉领域中仍然受到限制。在计算机视觉领域,目前已有大量工作表明模型对 CNN 的依赖不是必需的,当直接应用于图像块序列时,transformer 也能很好地执行图像分类任务。本文的目的是为学者介绍一个优秀的 vision transformer 的PyTorch实现,以便更快地开展相关实验。