补充一个multi-head self-attention

还有一种multi-head的self-attention,以2个head的情况为例: 由\(a^{i}\)生成的\(q^{i}\)进一步乘以2 个转移矩阵变为\(q^{i, 1}\)和\(q^{i, 2}\),同理由\(a^{i}\)生成的\(k^{i}\)进一步乘以2个转移矩阵变为\(k^{i, 1}\)和\(k^{i, 2}\),由\(a^{i}\)生成的\(v^{i}\)进一步乘以2个转移矩阵变为\(v^{i, 1}\)和\(v^{i, 2}\)。
接下来\(q^{i, 1}\)再与\(k^{i, 1}\)做attention,得到weighted sum的权重\(\alpha\),再与\(v^{i, 1}\)做weighted sum得到最终的\(b^{i, 1}(i=1,2, \ldots, N)\)。
同理得到\(b^{i, 2}(i=1,2, \ldots, N)\)。
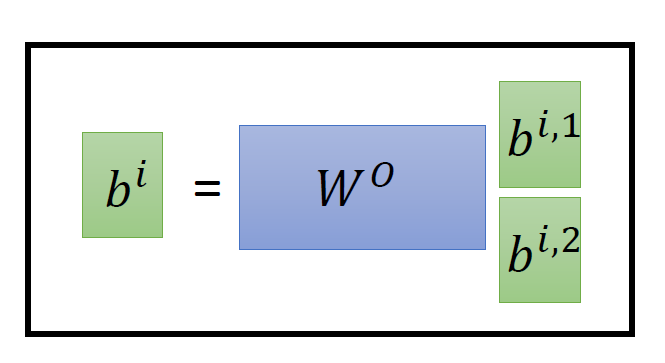
现在我们有了\(b^{i, 1}(i=1,2, \ldots, N) \in R(d, 1)\)和\(b^{i, 2}(i=1,2, \ldots, N) \in R(d, 1)\),可以把它们 concat起来,再通过一个transformation matrix调整维度,使之与刚才的\(b^{i}(i=1,2, \ldots, N) \in R(d, 1)\)维度一致。
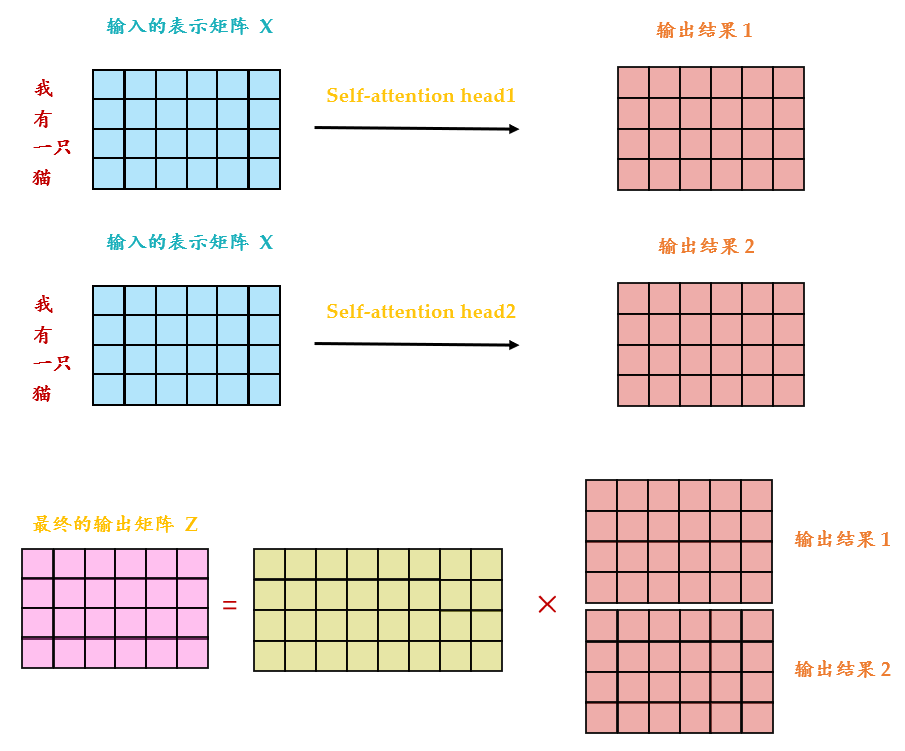
从下图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入\(X\)分别传 递到 2个不同的 Self-Attention 中,计算得到 2 个输出结果。
得到2个输出矩阵之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出\(Z\)。
可以看到Multi-Head Attention输出的矩阵\(Z\)与其输入的矩阵\(X\)的维度是一样的。
不同组别的query和key可以关注输入中不同的信息,比如global和local。