transformer原理分析和代码解读

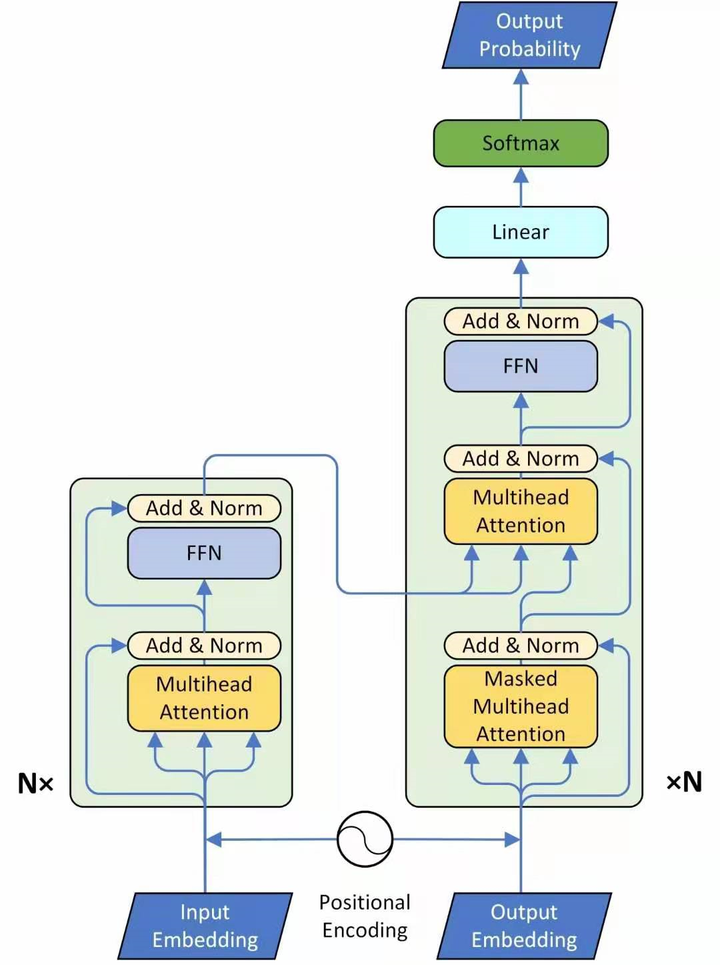
这个图为transformer的整体结构,左侧为 Encoder block,右侧为 Decoder block。
黄色圈中的部分为Multi-Head Attention,是由多个Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
先看左半部分的Encoder:
首先输入 X∈R(n_x,N) 通过一个Input Embedding的转移矩阵 W_x∈R(d,n_x) 变为了一个张量,即I∈R(d,N),再加上一个表示位置的Positional Encoding E∈R(d,N) ,得到一个张量。
之后就会进入Encoder block,该block会重复 N 次。第一层是一个multi-head attention。现在一个sequence I∈R(d,N) ,经过一个multi-head attention,会得到另一个sequence O∈R(d,N) 。
下一个Layer是Add & Norm,把multi-head attention layer的输入 I∈R(d,N) 和输出 O∈R(d,N) 进行相加以后,再做Layer Normalization。
接着是一个Feed Forward的前馈网络和一个Add & Norm Layer。
Encoder block的前2个Layer操作的表达式为:
\[O_1=Layer Normalization(I+Multi head SelfAttention(I))\]
后2个Layer操作的表达式为:
\[O_2=Layer Normalization(O_1+Feed Forward Network(O_1))\]
\[Block(I)=O_2\]
所以Encoder block的整体操作为:
\[Encoder(I)=Block(…Block(Block(I)))\]
\[N \quad times\]
现在来看Decoder的部分,输入包括2部分,下方是前一个time step的输出的embedding,即上文所述的 I∈R(d,N) ,再加上一个表示位置的Positional Encoding E∈R(d,N) ,得到一个张量,去往后面的操作。
首先是Masked Multi-Head Self-attention,masked的意思是使attention只会attend on已经产生的sequence, 在预测第 i 个输出时,就要将第 i+1 之后的sequence掩盖住,防止提前知道信息。
之后的操作与Encoder的部分类似,中间的attention不是self-attention,它的Key和Value来自Encoder,Query来自上一位置 Decoder 的输出。
但是要特别注意,编码可以并行计算,一次性全部Encode出来,而解码是像RNN一样顺序解出来的,因为要用上一个位置的输入当作attention的Query。